


Inverted Pendulum#
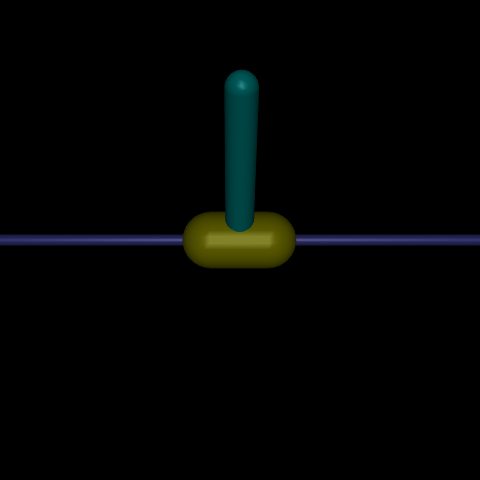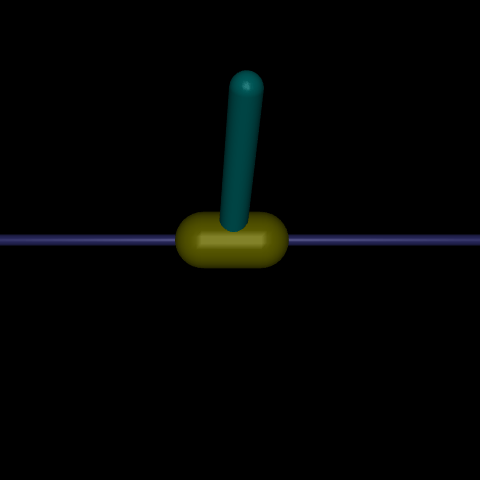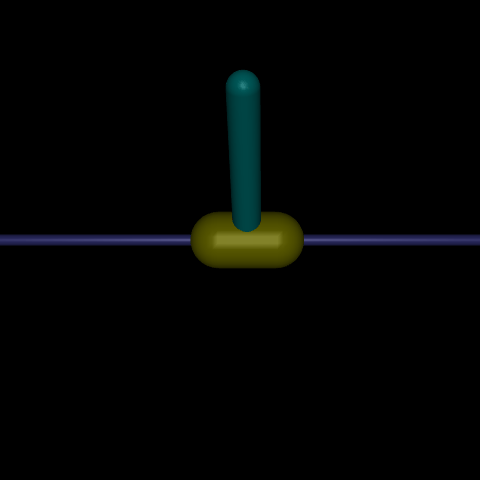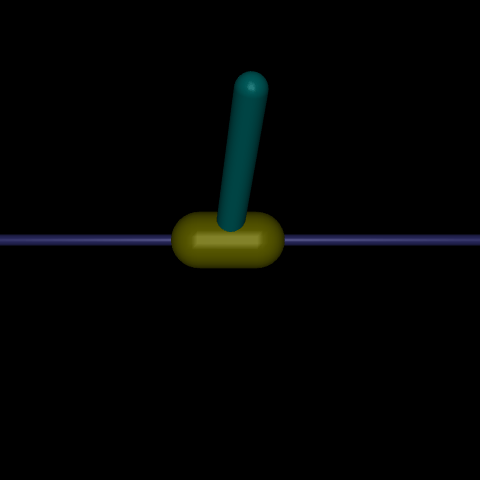
This environment is part of the Mujoco environments which contains general information about the environment.
Action Space |
|
Observation Space |
|
import |
|
Description#
This environment is the cartpole environment based on the work done by Barto, Sutton, and Anderson in “Neuronlike adaptive elements that can solve difficult learning control problems”, just like in the classic environments but now powered by the Mujoco physics simulator - allowing for more complex experiments (such as varying the effects of gravity). This environment involves a cart that can moved linearly, with a pole fixed on it at one end and having another end free. The cart can be pushed left or right, and the goal is to balance the pole on the top of the cart by applying forces on the cart.
Action Space#
The agent take a 1-element vector for actions.
The action space is a continuous (action) in [-3, 3], where action represents
the numerical force applied to the cart (with magnitude representing the amount of
force and sign representing the direction)
Num |
Action |
Control Min |
Control Max |
Name (in corresponding XML file) |
Joint |
Unit |
|---|---|---|---|---|---|---|
0 |
Force applied on the cart |
-3 |
3 |
slider |
slide |
Force (N) |
Observation Space#
The state space consists of positional values of different body parts of the pendulum system, followed by the velocities of those individual parts (their derivatives) with all the positions ordered before all the velocities.
The observation is a ndarray with shape (4,) where the elements correspond to the following:
Num |
Observation |
Min |
Max |
Name (in corresponding XML file) |
Joint |
Unit |
|---|---|---|---|---|---|---|
0 |
position of the cart along the linear surface |
-Inf |
Inf |
slider |
slide |
position (m) |
1 |
vertical angle of the pole on the cart |
-Inf |
Inf |
hinge |
hinge |
angle (rad) |
2 |
linear velocity of the cart |
-Inf |
Inf |
slider |
slide |
velocity (m/s) |
3 |
angular velocity of the pole on the cart |
-Inf |
Inf |
hinge |
hinge |
anglular velocity (rad/s) |
Rewards#
The goal is to make the inverted pendulum stand upright (within a certain angle limit) as long as possible - as such a reward of +1 is awarded for each timestep that the pole is upright.
Starting State#
All observations start in state (0.0, 0.0, 0.0, 0.0) with a uniform noise in the range of [-0.01, 0.01] added to the values for stochasticity.
Episode End#
The episode ends when any of the following happens:
Truncation: The episode duration reaches 1000 timesteps.
Termination: Any of the state space values is no longer finite.
Termination: The absolute value of the vertical angle between the pole and the cart is greater than 0.2 radian.
Arguments#
No additional arguments are currently supported.
import gymnasium as gym
env = gym.make('InvertedPendulum-v4')
There is no v3 for InvertedPendulum, unlike the robot environments where a
v3 and beyond take gymnasium.make kwargs such as xml_file, ctrl_cost_weight, reset_noise_scale, etc.
import gymnasium as gym
env = gym.make('InvertedPendulum-v2')
Version History#
v4: All MuJoCo environments now use the MuJoCo bindings in mujoco >= 2.1.3
v3: Support for
gymnasium.makekwargs such asxml_file,ctrl_cost_weight,reset_noise_scale, etc. rgb rendering comes from tracking camera (so agent does not run away from screen)v2: All continuous control environments now use mujoco-py >= 1.50
v1: max_time_steps raised to 1000 for robot based tasks (including inverted pendulum)
v0: Initial versions release (1.0.0)