


Basic Usage#
Gymnasium is a project that provide an API for all single agent reinforcement learning environments that include implementations of common environments: cartpole, pendulum, mountain-car, mujoco, atari, and more.
The API contains four key functions: make, reset, step and render that this basic usage will introduce you to. At the core of Gymnasium is Env which is a high level python class representing a markov decision process from reinforcement learning theory (this is not a perfect reconstruction missing several components of MDPs). Within gymnasium, environments (MDPs) are implements as Env along with Wrappers that can change the results passed to the user.
Initializing Environments#
Initializing environments is very easy in Gymnasium and can be done via the make function:
import gymnasium as gym
env = gym.make('CartPole-v1')
This will return an Env for users to interact with. To see all environments you can create, use gymnasium.envs.registry.keys().make includes a number of additional parameters to adding wrappers, specifying keywords to the environment and more.
Interacting with the Environment#
The classic “agent-environment loop” pictured below is simplified representation of reinforcement learning that Gymnasium implements.
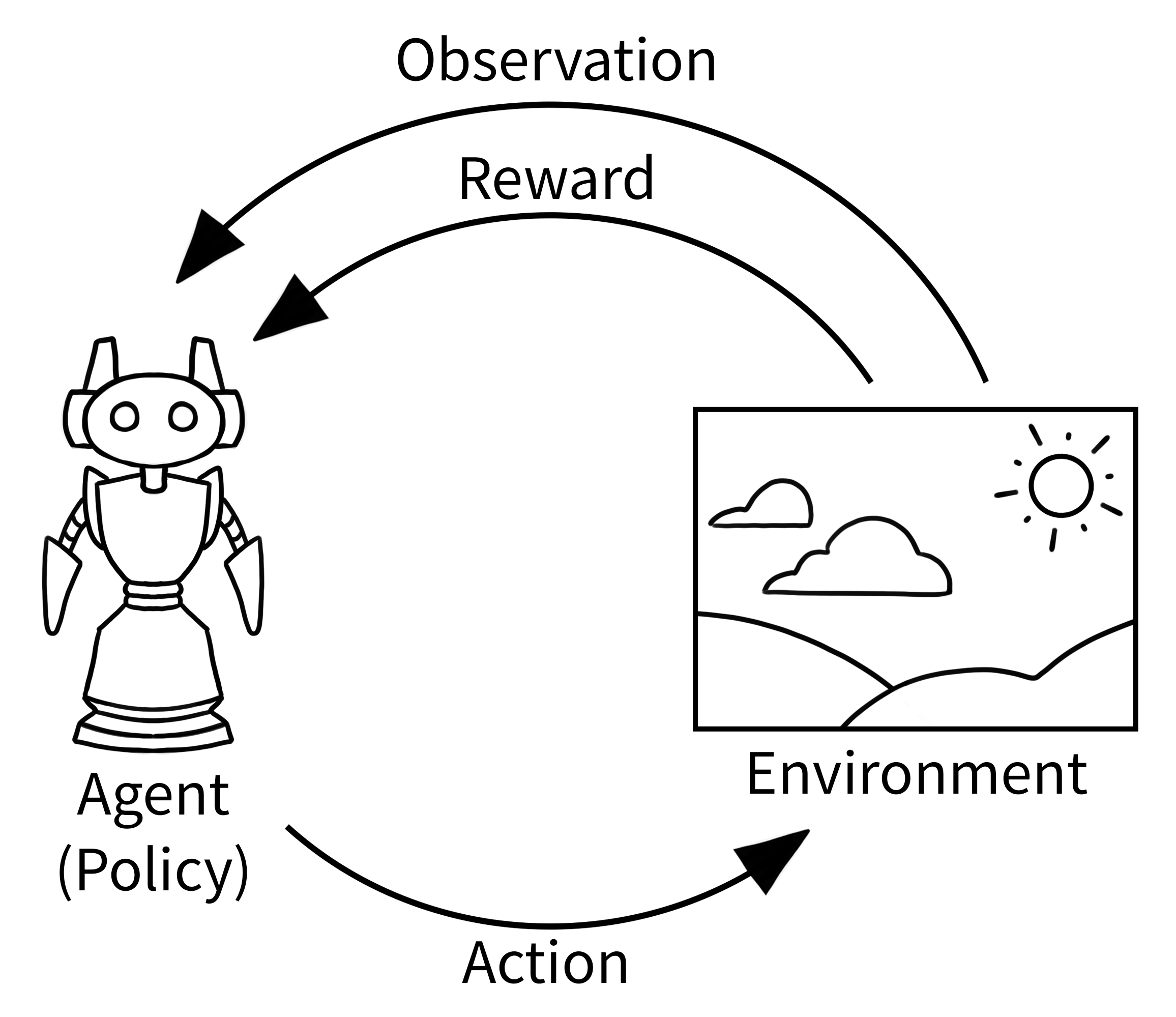
This loop is implemented using the following gymnasium code
import gymnasium as gym
env = gym.make("LunarLander-v2", render_mode="human")
observation, info = env.reset()
for _ in range(1000):
action = env.action_space.sample() # agent policy that uses the observation and info
observation, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
observation, info = env.reset()
env.close()
The output should look something like this:

Explaining the code#
First, an environment is created using make with an additional keyword "render_mode" that specifies how the environment should be visualised. See render for details on the default meaning of different render modes. In this example, we use the "LunarLander" environment where the agent controls a spaceship that needs to land safely.
After initializing the environment, we reset the environment to get the first observation of the environment. For initializing the environment with a particular random seed or options (see environment documentation for possible values) use the seed or options parameters with reset.
Next, the agent performs an action in the environment, step, this can be imagined as moving a robot or pressing a button on a games’ controller that causes a change within the environment. As a result, the agent receives a new observation from the updated environment along with a reward for taking the action. This reward could be for instance positive for destroying an enemy or a negative reward for moving into lava. One such action-observation exchange is referred to as a timestep.
However, after some timesteps, the environment may end, this is called the terminal state. For instance, the robot may have crashed, or the agent have succeeded in completing a task, the environment will need to stop as the agent cannot continue. In gymnasium, if the environment has terminated, this is returned by step. Similarly, we may also want the environment to end after a fixed number of timesteps, in this case, the environment issues a truncated signal. If either of terminated or truncated are true then reset should be called next to restart the environment.
Action and observation spaces#
Every environment specifies the format of valid actions and observations with the env.action_space and env.observation_space attributes. This is helpful for both knowing the expected input and output of the environment as all valid actions and observation should be contained with the respective space.
In the example, we sampled random actions via env.action_space.sample() instead of using an agent policy, mapping observations to actions which users will want to make. See one of the agent tutorials for an example of creating and training an agent policy.
Every environment should have the attributes action_space and observation_space, both of which should be instances of classes that inherit from Space. Gymnasium has support for a major of possible spaces are users need:
Box: describes an n-dimensional continuous space. It’s a bounded space where we can define the upper and lower limits which describe the valid values our observations can take.Discrete: describes a discrete space where {0, 1, …, n-1} are the possible values our observation or action can take. Values can be shifted to {a, a+1, …, a+n-1} using an optional argument.Dict: represents a dictionary of simple spaces.Tuple: represents a tuple of simple spaces.MultiBinary: creates an n-shape binary space. Argument n can be a number or a list of numbers.MultiDiscrete: consists of a series ofDiscreteaction spaces with a different number of actions in each element.
For example usage of spaces, see their documentation along with utility functions. There are a couple of more niche spaces Graph, Sequence and Text.
Modifying the environment#
Wrappers are a convenient way to modify an existing environment without having to alter the underlying code directly. Using wrappers will allow you to avoid a lot of boilerplate code and make your environment more modular. Wrappers can also be chained to combine their effects. Most environments that are generated via gymnasium.make will already be wrapped by default using the TimeLimit, OrderEnforcing and PassiveEnvChecker.
In order to wrap an environment, you must first initialize a base environment. Then you can pass this environment along with (possibly optional) parameters to the wrapper’s constructor:
>>> import gymnasium
>>> from gymnasium.wrappers import RescaleAction
>>> base_env = gymnasium.make("BipedalWalker-v3")
>>> base_env.action_space
Box([-1. -1. -1. -1.], [1. 1. 1. 1.], (4,), float32)
>>> wrapped_env = RescaleAction(base_env, min_action=0, max_action=1)
>>> wrapped_env.action_space
Box([0. 0. 0. 0.], [1. 1. 1. 1.], (4,), float32)
Gymnasium already provides many commonly used wrappers for you. Some examples:
TimeLimit: Issue a truncated signal if a maximum number of timesteps has been exceeded (or the base environment has issued a truncated signal).ClipAction: Clip the action such that it lies in the action space (of typeBox).RescaleAction: Rescale actions to lie in a specified intervalTimeAwareObservation: Add information about the index of timestep to observation. In some cases helpful to ensure that transitions are Markov.
For a full list of implemented wrappers in gymnasium, see wrappers.
If you have a wrapped environment, and you want to get the unwrapped environment underneath all the layers of wrappers (so that you can manually call a function or change some underlying aspect of the environment), you can use the .unwrapped attribute. If the environment is already a base environment, the .unwrapped attribute will just return itself.
>>> wrapped_env
<RescaleAction<TimeLimit<BipedalWalker<BipedalWalker-v3>>>>
>>> wrapped_env.unwrapped
<gymnasium.envs.box2d.bipedal_walker.BipedalWalker object at 0x7f87d70712d0>